
Docling is a powerful, open-source toolkit that turns everyday documents into clean, structured data—ready to plug into large language models (LLMs), search tools, chatbots, and other AI systems.
Whether you’re building a document question answering system, doing RAG (retrieval-augmented generation), or just want better ways to extract information from messy PDFs , Docling gives you the tools to do it.
And if you don’t want to install anything? You can try it right now at https://docling.xyz — a hosted version that works in your browser.
What Is Docling?
Docling is a document processing pipeline that takes in various file types—like PDF, DOCX, PPTX, HTML, images, and even audio—and turns them into structured, readable formats like JSON, Markdown, or clean HTML. But what really makes this toolkit stand out is how much layout and structure it preserves.
Let’s say you upload a multi column scientific PDF full of tables, charts, and figures. Traditional tools might give you a wall of text or garbled output. Docling, on the other hand, will detect the columns, identify tables, and organize the content as close to the original layout as possible—while still making it usable for AI applications.
Key Features at a Glance:
- 📄 Supports many formats: PDF, DOCX, PPTX, HTML, images, audio
- 🔍 Smart layout detection: Preserves columns, tables, headings, etc.
- 📤 Multiple output types: Markdown, JSON, HTML, and more
- 🧠 AI-ready: Built for integration with LLMs, RAG pipelines, LangChain, and others
- 🔗 Hosted version: Try it online at docling.xyz
- 🛠️ Open-source toolkit: Available on GitHub at github.com/docling-project/docling
Why Use Docling?
Here are the top reasons developers and AI teams are using it:
1. It Works with Messy, Real-World Documents
Many tools struggle with anything beyond simple pages. Docling handles multi-column layouts, embedded tables, scanned pages, and even noisy PDFs. Whether it's a government report or a poorly formatted scan, Docling can make sense of it.
2. Perfect for AI Pipelines
Large language models (LLMs) are powerful—but only when they get clean, structured input. Docling was designed specifically to feed these models. It's perfect for:
- Retrieval-augmented generation (RAG)
- Document QA (question answering)
- Fine-tuning or pre-processing large corpora
- Enterprise document search
3. Open Source and Community-Driven
No black boxes here. Docling is open-source, fully transparent, and part of the LF AI & Data Foundation. You can run it locally, modify it, or integrate it into your systems freely.
→ Check out the code on GitHub
4. Modular and Extensible
Need to swap out an OCR engine? Use your own layout detector? Customize export formats? Docling’s architecture is flexible and modular, so you’re not locked into one way of doing things.
Docling's Core Tools
Docling comes with a powerful set of tools and models under the hood. Here’s a quick look at the components that make the magic happen:
🧱 1. The Pipeline
Docling’s processing pipeline is built like this:
Input (PDF, DOCX, etc.) → Layout Detection → Table Recognition → Content Extraction → Document Assembly → Export
Each of these steps is modular and can be customized.
🔍 2. Layout Models
Docling uses top-tier models to detect layout elements:
- DocLayNet – for general layout detection
- TableFormer – for precise table understanding
- Heron – a newer, high-accuracy layout model
🧠 3. Vision-Language Models (VLMs)
Docling also includes small but powerful AI models that help convert documents intelligently:
- SmolDocling – a lightweight VLM that processes documents end-to-end
- Granite-Docling – a compact model (258M parameters) designed by IBM to preserve structure in low-resource settings
🏷️ 4. DocTags
This is Docling’s custom markup system—think of it like HTML, but built for documents. It captures structural cues like sections, headers, tables, paragraphs, etc. This helps LLMs understand the layout and purpose of each part of the document.
🔄 5. Export Formats
You can export documents into:
- Markdown – great for readable content
- JSON – easy to parse in code or feed into an LLM
- HTML – for display in web apps
- Chunked Output – for feeding into vector databases or RAG systems
- DocTags – preserves structure better than raw HTML
How to Use Docling
You can use Docling in two main ways: through the hosted web version or by running it locally via CLI or Python.
🚀 Option 1: Try the Hosted Version (No Setup)
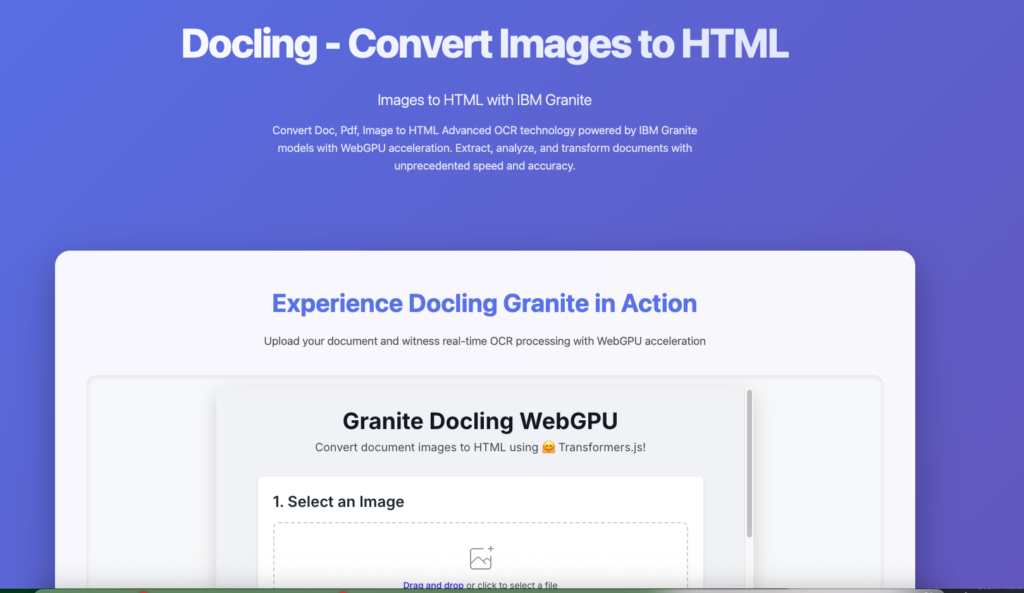
Go to https://docling.xyz
- Upload your document (PDF, DOCX, etc.)
- Choose output format (Markdown, JSON, HTML)
- View, download, or copy the structured output
Great for:
- Quick one-off conversions
- Trying the tool without setup
- Sharing with teammates or stakeholders
🖥️ Option 2: Use the CLI or Python API
If you're a developer or working with large volumes of data, you’ll want to install Docling locally.
🔧 Installation (via pip)
pip install docling
🕹️ CLI Usage
docling process myfile.pdf --output-format markdown
🐍 Python Usage
from docling import DoclingDocument
doc = DoclingDocument.from_file("report.pdf")
output = doc.to_markdown()
print(output)
→ View full documentation and source at github.com/docling-project/docling
Docling also includes integrations with:
- LangChain (
DoclingLoader) - LlamaIndex
- Haystack
You can easily plug it into your AI pipeline for search, RAG, or document chatbots.
You can also check our other AI dev tools: 10 Best AI Tools for Developers 2025
Tips & Best Practices
✅ Use chunked exports for LLMs – improves prompt length control and context handling
✅ Use DocTags for better structure awareness in fine-tuned models
✅ Scanned documents? Docling includes OCR engines to extract text from images
✅ Messy layouts? Try different layout models (Heron, DocLayNet) to compare
✅ Non-English content? Multilingual support is growing—watch for updates!
Real-World Example: Processing a Technical Report
Imagine you’re working with a 40-page scientific report in PDF format. It’s two columns, packed with charts and tables.
With a traditional PDF parser, you’d get a mess—tables split up, text flowing out of order, and important headings lost.
With Docling, you get:
- Headings and sections preserved
- Tables cleanly extracted and labeled
- Figures listed or linked
- Text in correct reading order
You can export the entire thing to Markdown and immediately use it in a chatbot or QA system. If you chunk it, you can feed each section into a vector database for search and retrieval.
The Future of Docling
Docling is already one of the most advanced open-source document toolkits available—but there’s more coming. Future updates will focus on:
- Better chart and figure handling
- Multilingual support
- Agentic document manipulation (AI agents that act on documents)
- Improved metadata extraction
It’s also growing thanks to community contributions. If you have use cases, feature requests, or improvements, jump into the GitHub repo or community forums and get involved.
Conclusion
Docling solves a real problem: getting documents ready for AI. It’s open, flexible, and built with modern AI use cases in mind. Whether you’re dealing with a pile of PDFs, building a document chatbot, or developing advanced RAG pipelines, Docling gives you the tools to turn raw files into intelligent data.
You can:
- Try it instantly at https://docling.xyz
- Use it in code with the CLI or Python API
- Explore the source at https://github.com/docling-project/docling
- Integrate it with LangChain, LlamaIndex, and more
If you work with documents and AI, Docling is the missing link you’ve been looking for.
Ludjon, who co-founded Codeless, possesses a deep passion for technology and the web. With over a decade of experience in constructing websites and developing widely-used WordPress themes, Ludjon has established himself as an accomplished expert in the field.





Comments